The Kolakoski sequence is a strange but kind of fun sequence of integers.
All the members of the sequence are either 1 or 2. The sequence is made up of successive “runs” of 1’s and 2’s. Sometimes a run is one element long, and sometimes it is two elements long. If a particular run is made up of 1’s, the next run must be made up of 2’s. And vice versa.
The nth element of the sequence tells you how long the nth run of the sequence is.
The first element of the sequence is a 1.
So the first run has only one 1 in it, which means that the next element has to be a two. So now the sequence is 1, 2
But the second element of the sequence being a 2 tells us that the second run has to be two elements long, so the sequence has to be 1, 2, 2.
So we have first three elements (1, 2, 2), and the first two runs (1, and then 2,2).
Now let’s work on the third run. The third element of the sequence is a 2, so the third run must be two elements long, and since the second run was made up of 2’s, the third run must be made up of 1’s (two of them). So now the sequence is 1, 2, 2, 1, 1
Now let’s go on to the fourth run. It has to be made up of 2’s, since the third run was made up of 1’s, and the fourth element in the sequence, which tells us how long the fourth run is, is a 1. So now the sequence is 1, 2, 2, 1, 1, 2.
One more time. Let’s look at the fifth run. It has to be made up of 1’s, since the fourth run was made up of 2’s. How many? Well, the fifth element in the sequence is a 1, so the fifth run is one element long, and that element has to be a 1. So now the sequence is 1, 2, 2, 1, 1, 2, 1.
And so on.
The sequence is described in the Online Encyclopedia of Integer Sequences, in which it is sequence A00002, and in this Wikipedia article.
It has not yet been proved whether the sequence, as it gets longer and longer, converges to having closer and closer to 1/2 of its elements be 1’s, but it has been proved that it is very close, and in computation it seems to get closer the larger the sequence gets. See the Wikipedia article for more on that.
So …
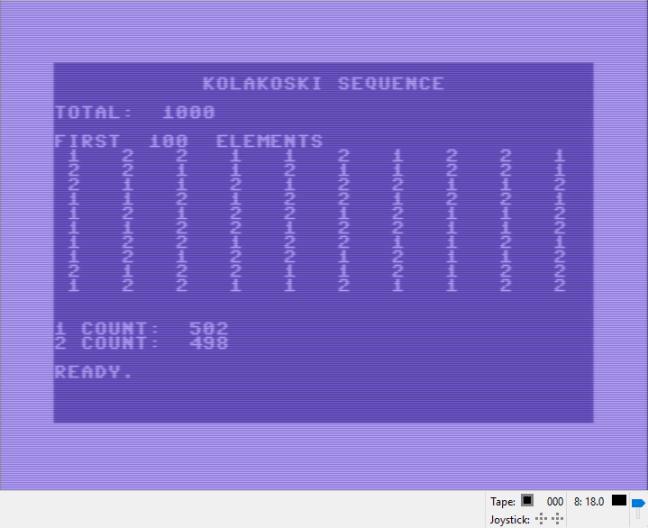
I programmed my C64 to calculate the sequence out to a limit of 1000 elements, and to print the first 100 elements, and then to report on the number of 1’s and 2’s in the first 1000 elements.
First, here is the program:
5 rem ================================ 6 rem 10 rem exploring the kolakoski sequence 15 rem 20 rem ================================ 50 m = 1000 100 dim a%(m+1) 120 a%(1) = 1 130 c = 2 140 cc = 1 150 if cc >= m then goto 5000 160 d = a%(cc) 170 e = 2 180 if d = 2 then e = 1 185 cc = cc + 1 190 a%(cc) = e 210 if a%(c) = 2 then cc = cc + 1:a%(cc)= e 220 c = c + 1 230 goto 150 220 c = c + 1 230 goto 150 5000 ct1 = 0 : ct2 = 0 5020 print chr$(147) 5025 print " kolakoski sequence": print 5030 print "total: ";m 5035 print 5040 mm = m : if mm > 100 then mm = 100 5045 print "first ";mm; " elements" 5050 for i = 1 to m 5100 if i <= mm then print a%(i);" "; 5150 if a%(i) = 1 then t1 = t1 + 1 5170 if a%(i) = 2 then t2 = t2 + 1 5200 next i 5250 print:print 5300 print "1 count: ";t1 5310 print "2 count: ";t2
Here is the screen shot:

