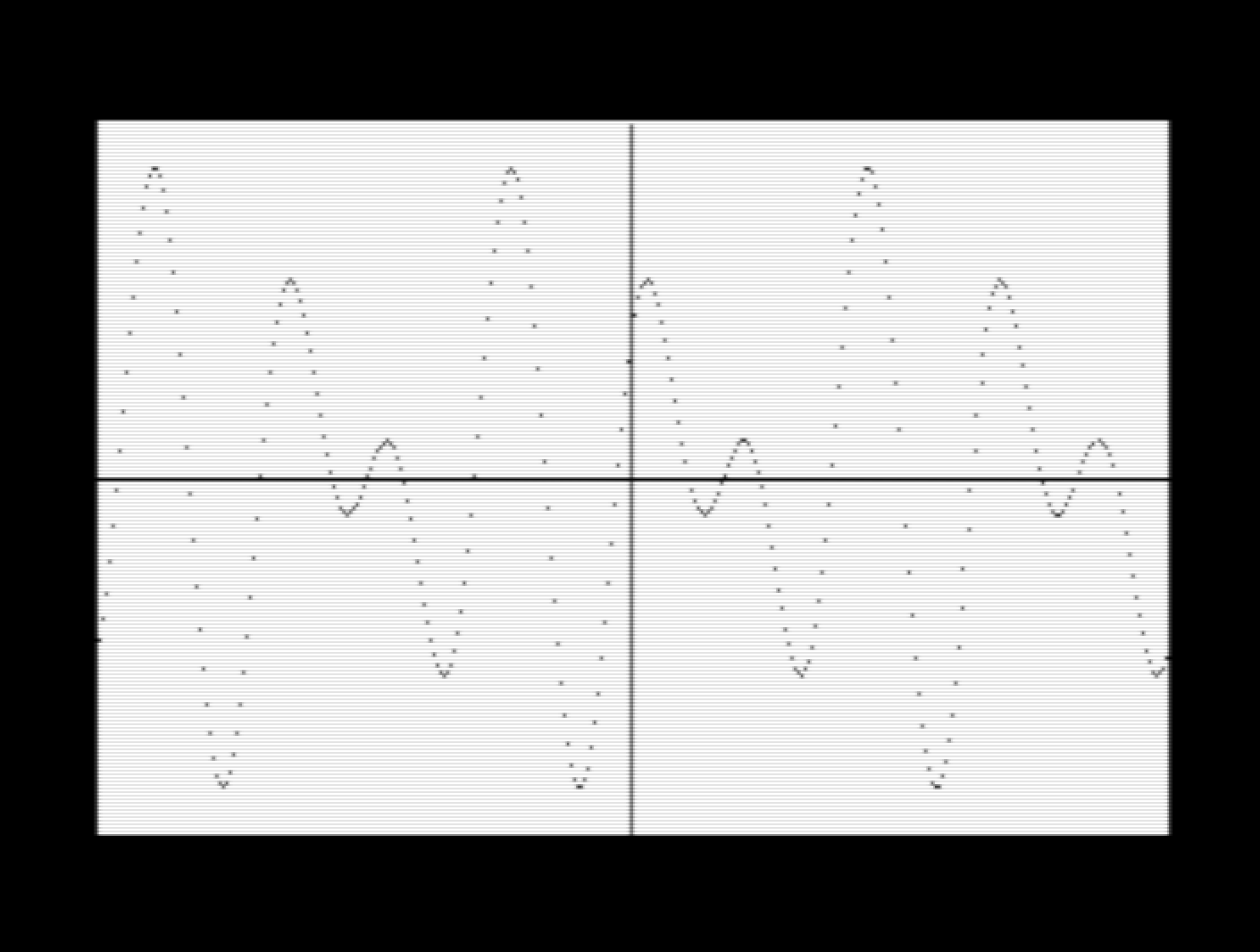
Well, it took 36 hours, but at last my C64 finished calculating and drawing the non-diverging section of the Mandelbrot set.
Mandelbrot Set on a C64
Here is the code, in Basic:
10 rem ** mandelbrot hires 20 rem 40 yu = 1.5 : yd = -1.5 50 xu = 2 : xd = -2 60 xr = xu – xd : yr = yu – yd 70 xs = xr/320 : ys = yr/200 100 rem set vic address 110 v = 53248 120 rem set graphic ram address 130 ga = 8192 140 rem set video ram address 150 vr = 1024 160 rem set border to black 170 poke v+32,0
500 gosub 20000 : rem turn on hires 510 gosub 21000 : rem graphic ram area 520 gosub 22000 : rem set color ram 530 gosub 23000 : rem clr graphic ram
1000 for xc = 0 to 319 1010 for yc = 0 to 199 1012 x0 = xc*(xr/320) + xd
1014 y0 = (yc-200)*(yr/200) – yd 1020 x = 0 1030 y = 0 1040 it = 0 1050 mx = 250 1060 a = x*x+y*y 1070 if a > 4 then goto 1200 1080 b = x*x-y*y + x0 1090 y = 2*x*y + y0 1100 x = b 1110 it = it + 1 1120 if it < mx then goto 1060 1150 gosub 30000 : rem set (xc,yc) 1200 next yc 1210 next xc 1400 poke 198,0 : wait 198,1 1450 gosub 24000 1500 end
20000 rem turn on hi res graphics 20010 rem 1. set bits 5/6 of v+17 20020 rem 2. clr bit 4 of v+22 20030 poke v+17,peek(v+17) or (11*16) 20040 poke v+22,peek(v+22) and (255-16) 20050 return 21000 rem set graphic ram area 21010 rem 1. set bit 3 of v+24 21020 poke v+24, peek(v+24) or 8 21030 return 22000 rem set color ram 22010 rem 1. color ram is 1024-2023 22020 rem 2. set background 1 – white 22030 rem 3. set foreground 0 – black 22040 co = 0*16 + 1 22050 for i = vr to vr+1000 22060 poke i,co 22070 next i 22080 return 23000 rem clear graphic ram 23010 rem 1. graphic ram is ga to 23020 rem ga + 8000 23030 for i = ga to ga +8000 23040 poke i,0 23050 next i 23060 return
24000 rem turn graphics off 24010 rem 1. clr bits 5/6 of v+17 24020 rem 2. clr bit 4 of v+22 24030 rem 3. clr bit 3 of v+24 24040 poke v+17,peek(v+17) and (255-96) 24050 poke v+22,peek(v+22) and (255-16) 24060 poke v+24,peek(v+24) and (255-8) 24070 return 30000 rem set pixel 30010 ra = 320*int(yc/8)+(yc and 7)
30020 ba = 8*int(xc/8) 30030 ma = 2^(7-(xc and 7)) 30040 ad = ga + ra + ba 30050 poke ad,peek(ad) or ma 30060 return 31000 rem clr pixel 31010 ra = 320*int(yc/8)+(yc and 7)
31020 ba = 8*int(xc/8) 31030 ma = 255-2^(7-(xc and 7)) 31040 ad = ga + ra + ba 31050 poke ad,peek(ad) or ma 31060 return
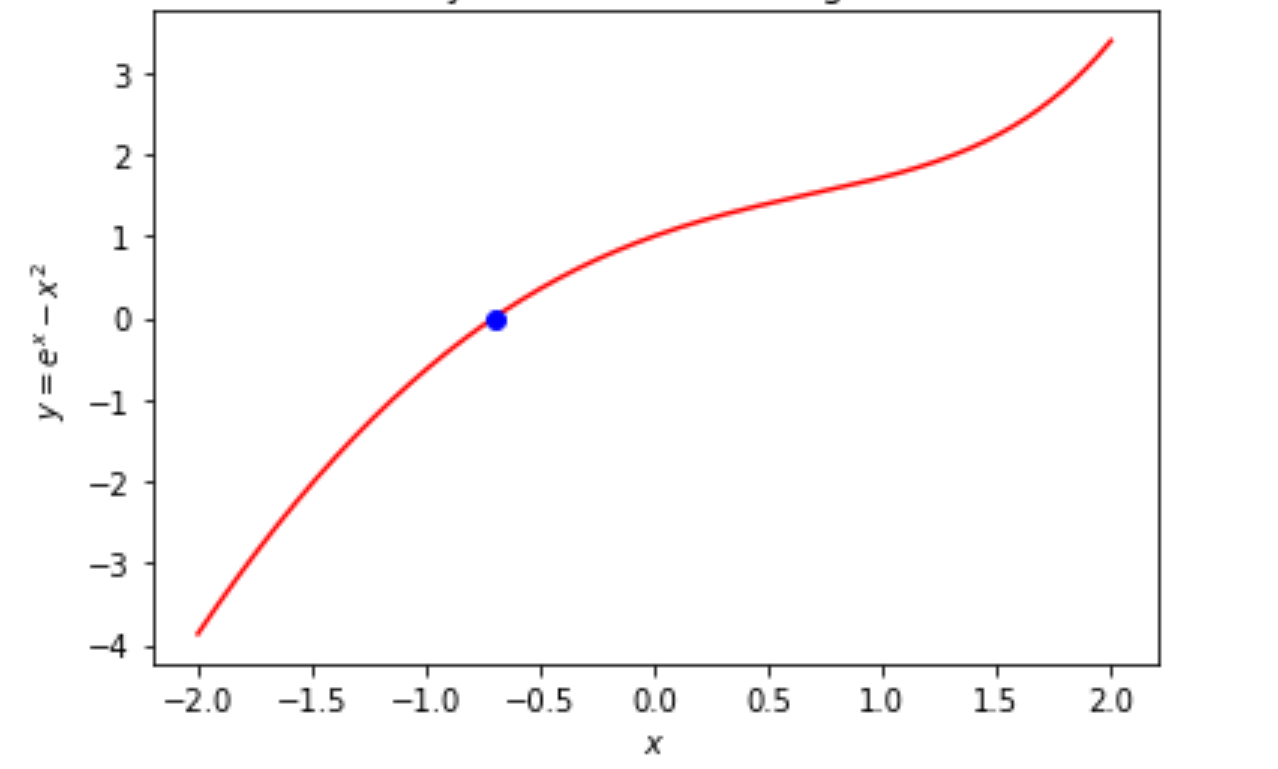
I wrote a program to plot a function in hi-res graphics mode on the C64. It is entirely in BASIC, so it is mind-numbingly slow, but it works, and can be used to plot some fairly interesting functions.
This mode only allows one background color and one foreground color for each 8×8 block of pixels. It would, I suppose, be possible to plot multiple functions in multiple colors, but the intersections would be strange, as each 8×8 block can only have two colors, including the background. An obvious next step is to use the multi-color bitmap mode, but which this would allow four colors in any given 8×8 block, it would reduce the resolution from 320×200 down to 160×200. I will try this soon.
Another obvious improvement will be to move much of the setup stuff (like erasing the graphics ram ($2000-$3fff)) down into machine language, which would speed things up significantly.
Here is the plot of f(x) = sin(x) + sin(1.5*x + pi/2)
And here is the code:
10 rem *** funcplot
20 rem
30 pi = 3.141592653
40 yu = 2.2 : yd = -2.2
50 xu = 6pi : xd = -6pi
60 xr = xu - xd : yr = yu - yd
70 xs = xr/320 : ys = yr/200
80 def fn f(x) = sin(x) + sin(1.5*x + pi/2)
100 rem set vic address
110 v = 53248
120 rem set graphic ram address
130 ga = 8192
140 rem set video ram address
150 vr = 1024
160 rem set border to black
170 poke v+32,0
500 gosub 20000 : rem turn on hires
510 gosub 21000 : rem graphic ram area
520 gosub 22000 : rem set color ram
530 gosub 23000 : rem clr graphic ram
1000 rem draw x axis
1005 y=0 : yc=int(200-(y-yd)*(200/yr))
1010 for xc = 0 to 319
1020 gosub 30000 : rem set (xc,yc)
1030 next xc
1100 rem draw y axis
1110 x = 0
1120 for yc = 1 to 200
1130 xc = int((x-xd)*(320/xr))
1140 gosub 30000 : rem set (xc,yc)
1150 next yc
1300 rem plot function
1310 for x = xd to xu step xs
1320 y = fn f(x)
1330 xc = int((x-xd)*(320/xr))
1340 yc = int(200-(y-yd)*(200/yr))
1350 gosub 30000 : rem set (xc,yc)
1360 next x
1400 poke 198,0 : wait 198,1
1450 gosub 24000
1500 end
20000 rem turn on hi res graphics
20010 rem 1. set bits 5/6 of v+17
20020 rem 2. clr bit 4 of v+22
20030 poke v+17,peek(v+17) or (11*16)
20040 poke v+22,peek(v+22) and (255-16)
20050 return
21000 rem set graphic ram area
21010 rem 1. set bit 3 of v+24
21020 poke v+24, peek(v+24) or 8
21030 return
22000 rem set color ram
22010 rem 1. color ram is 1024-2023
22020 rem 2. set background 1 - white
22030 rem 3. set foreground 0 - black
22040 co = 0*16 + 1
22050 for i = vr to vr+1000
22060 poke i,co
22070 next i
22080 return
23000 rem clear graphic ram
23010 rem 1. graphic ram is ga to
23020 rem ga + 8000
23030 for i = ga to ga +8000
23040 poke i,0
23050 next i
23060 return
24000 rem turn graphics off
24010 rem 1. clr bits 5/6 of v+17
24020 rem 2. clr bit 4 of v+22
24030 rem 3. clr bit 3 of v+24
24040 poke v+17,peek(v+17) and (255-96)
24050 poke v+22,peek(v+22) and (255-16)
24060 poke v+24,peek(v+24) and (255-8)
24070 return
30000 rem set pixel
30010 ra = 320*int(yc/8)+(yc and 7)
30020 ba = 8*int(xc/8)
30030 ma = 2^(7-(xc and 7))
30040 ad = ga + ra + ba
30050 poke ad,peek(ad) or ma
30060 return
31000 rem clr pixel
31010 ra = 320*int(yc/8)+(yc and 7)
31020 ba = 8*int(xc/8)
31030 ma = 255-2^(7-(xc and 7))
31040 ad = ga + ra + ba
31050 poke ad,peek(ad) or ma
31060 return
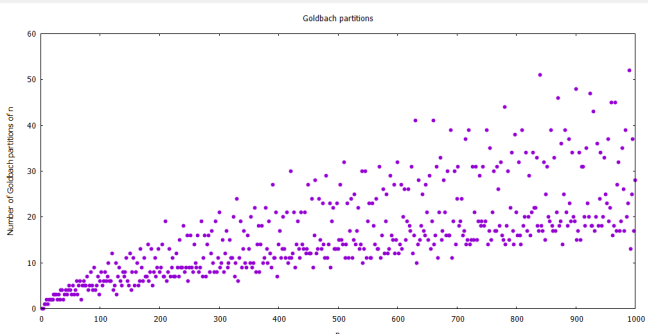
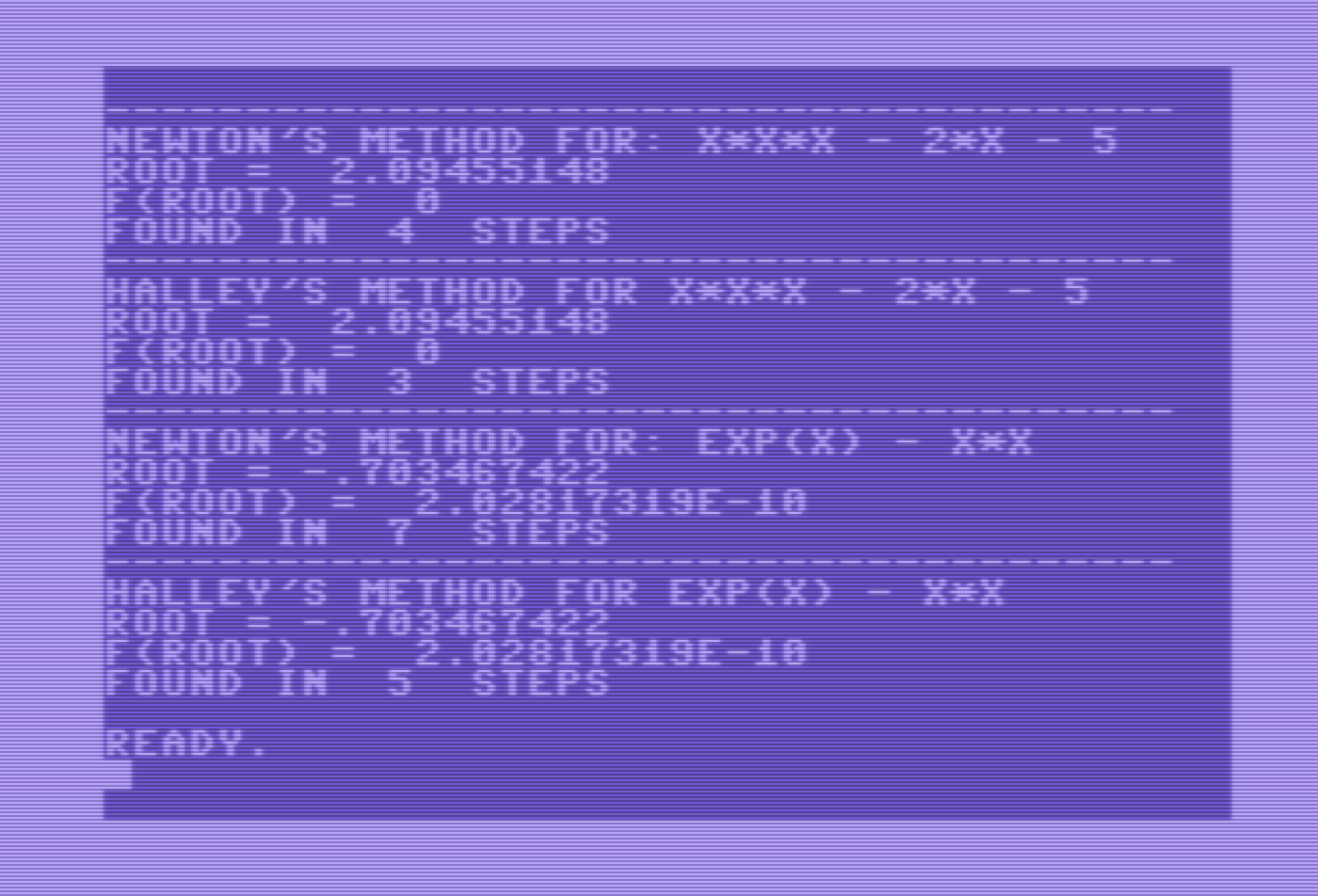
The Goldbach Conjecture states that every even integer greater than two can be expressed as a sum of two primes.
I programmed my C64 in Basic to ask the question “How many ways can a particular even integer be expressed as the sum of two primes?” So, for instance, the number 10 can be expressed as 3+7 or as 5+5, so two ways. The number 12 can be expressed as 5+7, so only one way. The number 22 can be expressed as 11+11 or as 19+3 or as 17+5, so three ways.
I left the program running for twelve hours, to calculate the Goldbach partitions of all even integers from six to one thousand. I’m very sure that there are much more efficient routines, which would run faster, but it is at least clear that it can be done.
Note that the Goldbach conjecture is not proven. The Wikipedia article here states that the conjecture has been tested by computers for numbers up to 4 x 10^18. But I only went as high as 1000.
Here is a plot of my results (not on the C64, but rather using gnuplot on Windows.
And here is the code:
50 qm = 1000
100 rem get primes up to 1000
200 dim p%(400)
220 p%(1) = 2
230 pc = 1
240 n = 3
300 for i = 1 to pc
310 w = n/p%(i)
320 if w = int(w) then 400
330 next i
340 pc = pc + 1
350 p%(pc) = n
355 print n
400 for i = 1 to 1: next i: n = n+1
410 if n < qm then goto 300
1000 rem get golbach numbers
1010 dim gb%(501)
1020 rem gb%(1) = 0 and gb%(2) = 0
1030 rem because 2 and 4 have no
1040 rem goldbach partitions
1050 gb%(1) = 0 : gb%(2) = 0
1060 q2 = int(qm/2)
1100 for m = 3 to q2
1110 n = m*2
1120 ct = 0
1130 for i = 1 to pc
1140 if p%(i) > n then goto 1200
1150 pr = n - p%(i)
1160 pf = 0
1162 for j = 1 to pc
1164 if p%(j) = pr then pf = 1:goto 1195
1166 if p%(j) > pr then goto 1200
1168 next j
1195 if pf = 1 then ct = ct + 1
1200 for j = 1 to 1:nextj:next i
1210 if (ct/2) <> int(ct/2) then ct = ct + 1
1220 ct = int(ct/2)
1250 print n,ct
1260 gb%(m) = ct
1300 next m
2000 open 2,8,2,"@:goldlist,s,w"
2010 for q = 1 to int(qm/2)
2020 print#2,q*2,gb%(q)
2030 next q
2040 close 2
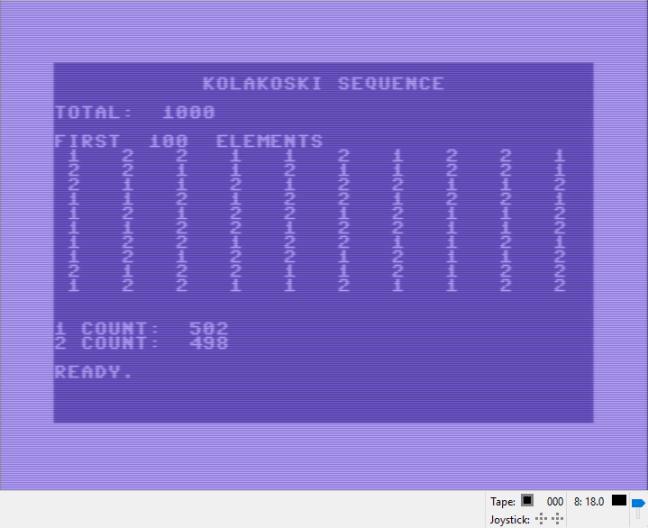
The Kolakoski sequence is a strange but kind of fun sequence of integers.
All the members of the sequence are either 1 or 2. The sequence is made up of successive “runs” of 1’s and 2’s. Sometimes a run is one element long, and sometimes it is two elements long. If a particular run is made up of 1’s, the next run must be made up of 2’s. And vice versa.
The nth element of the sequence tells you how long the nth run of the sequence is.
The first element of the sequence is a 1.
So the first run has only one 1 in it, which means that the next element has to be a two. So now the sequence is 1, 2
But the second element of the sequence being a 2 tells us that the second run has to be two elements long, so the sequence has to be 1, 2, 2.
So we have first three elements (1, 2, 2), and the first two runs (1, and then 2,2).
Now let’s work on the third run. The third element of the sequence is a 2, so the third run must be two elements long, and since the second run was made up of 2’s, the third run must be made up of 1’s (two of them). So now the sequence is 1, 2, 2, 1, 1
Now let’s go on to the fourth run. It has to be made up of 2’s, since the third run was made up of 1’s, and the fourth element in the sequence, which tells us how long the fourth run is, is a 1. So now the sequence is 1, 2, 2, 1, 1, 2.
One more time. Let’s look at the fifth run. It has to be made up of 1’s, since the fourth run was made up of 2’s. How many? Well, the fifth element in the sequence is a 1, so the fifth run is one element long, and that element has to be a 1. So now the sequence is 1, 2, 2, 1, 1, 2, 1.
It has not yet been proved whether the sequence, as it gets longer and longer, converges to having closer and closer to 1/2 of its elements be 1’s, but it has been proved that it is very close, and in computation it seems to get closer the larger the sequence gets. See the Wikipedia article for more on that.
So …
I programmed my C64 to calculate the sequence out to a limit of 1000 elements, and to print the first 100 elements, and then to report on the number of 1’s and 2’s in the first 1000 elements.
First, here is the program:
5 rem ================================
6 rem
10 rem exploring the kolakoski sequence
15 rem
20 rem ================================
50 m = 1000
100 dim a%(m+1)
120 a%(1) = 1
130 c = 2
140 cc = 1
150 if cc >= m then goto 5000
160 d = a%(cc)
170 e = 2
180 if d = 2 then e = 1
185 cc = cc + 1
190 a%(cc) = e
210 if a%(c) = 2 then cc = cc + 1:a%(cc)= e
220 c = c + 1
230 goto 150
220 c = c + 1
230 goto 150
5000 ct1 = 0 : ct2 = 0
5020 print chr$(147)
5025 print " kolakoski sequence": print
5030 print "total: ";m
5035 print
5040 mm = m : if mm > 100 then mm = 100
5045 print "first ";mm; " elements"
5050 for i = 1 to m
5100 if i <= mm then print a%(i);" ";
5150 if a%(i) = 1 then t1 = t1 + 1
5170 if a%(i) = 2 then t2 = t2 + 1
5200 next i
5250 print:print
5300 print "1 count: ";t1
5310 print "2 count: ";t2
This post is a consideration of the C64 keyboard. It is not exhaustive, and it is not systematic. I just want to consider a couple of topics: the keyboard matrix, keyboard codes, the conversion tables, and the keyboard buffer.
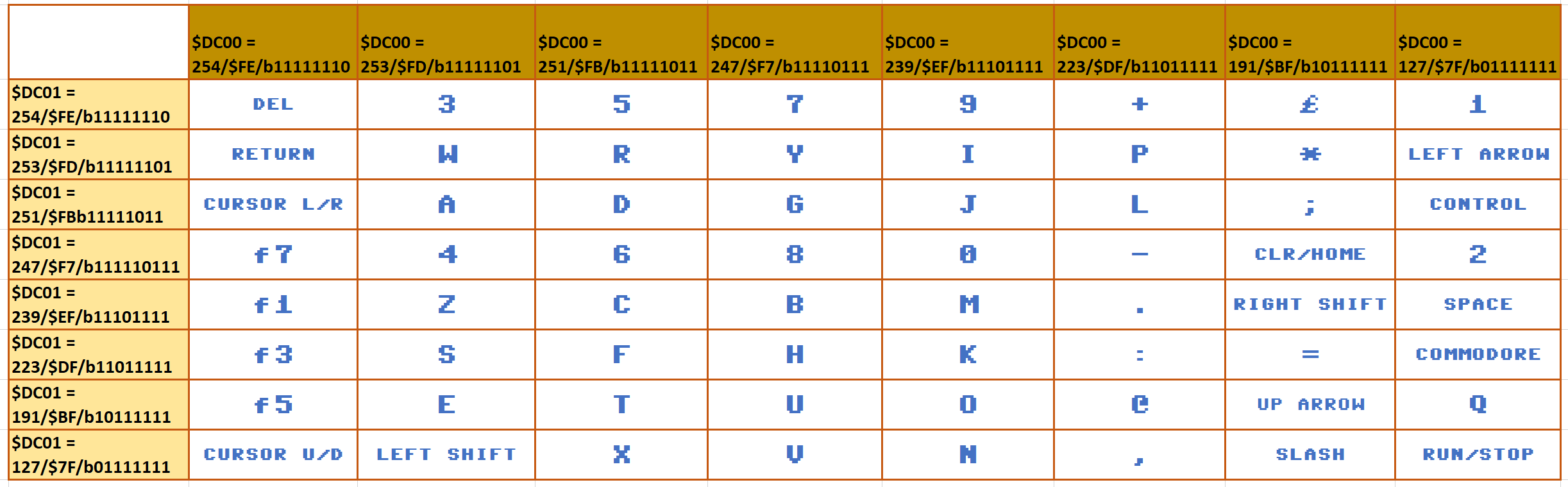
When a key is pressed on the keyboard on the Commodore 64, the kernal tries to read the keyboard matrix.
First, here is what the matrix looks like – the image is from the Commodore 64 Service Manual:
C64 Keyboard Matrix
We can watch the keyboard matrix work ourselves, using a BASIC program.
First, we need to turn off the kernal IRQ handler. This link tells us how to do that. Basically, we need to put a zero in the first bit of byte 56334 ($DC0E). Doing this will disable the keyboard, so we want to turn the IRQ handler back on at the end of the program, by putting a one in the first bit of byte 56334 ($DC0E). I turn the handler off in line 10 and back on in line 1000.
Now we are ready to probe the keyboard matrix. Here’s how that works. First, we poke a byte into $DC00 (56320) that indicates which set of eight possible characters we want to test for. In that byte, seven of the eight bits will be high, and one of the bits will be low – the low byte indicates which set of characters we are looking for (which row in the matrix we are probing). So the possible values are:
254 (b11111110) for row 0
253 (b11111101) for row 1
251 (b11111011) for row 2
247 (b11110111) for row 3
239 (b11101111) for row 4
223 (b11011111) for row 5
191 (b10111111) for row 6
127 (b01111111) for row 7
In the program below, I set the row byte in line 100. In the example, we are reading row 0.
Then, from 120 to 150 a FOR/NEXT loop waits for a key to be pressed. We can read the column number of the key pressed in byte $DC01 (56321). If no key is being pressed, that position will hold an $FF (255). If a key is being pressed, it will hold the column number of the pressed key, using the same format as for the rows above (254 -> 0, 253 -> 1, 251 -> 2, etc.) Thus, the number we poked into $DC00 and the number we read peeked from $DC01 gives us 8 x 8 or 64 possible characters as we see in the image from the service manual above.
Here is the code:
10 POKE 56334, PEEK(56334) AND 254
100 POKE 56320, 254
120 FOR I = 1 TO 5000
130 X = PEEK(56321)
140 IF X <> 255 THEN PRINT X : GOTO 1000
150 NEXT I
1000 POKE 56334, PEEK(56334) OR 1
Here is the matrix that I worked out, by putting all eight row values into $DC00 in line 100, then pushing keys until one of them gives a value that is not $FF in $DC01. I used my real C64C to be sure I was seeing what the real keyboard matrix looked like, rather than an artifact of WinVICE.
It is the same as the one from the manual, except that I reorganized the rows and columns to go in numeric order of the byte they contain, rather than trying to preserve any of the geography of the actual keyboard.
When the matrix has been read, the keyboard code is placed in the zero page memory position 203 ($CB). Then, before the keyboard is scanned again, the value in 203 is moved to 197 ($C5). When no key is being pressed, the value 64 ($40) is placed in 203, then is moved to 197 before the next scan. So, the situation that indicates “a new key has been pressed” is that 197 contains 64 and 203 contains a value less than 64.
This little program tests this. Because the keyboard matrix scan is fast and BASIC is slow, I have to press a key several times in order to have BASIC catch the transition between not pressed and pressed – awkward, but it demonstrates the concept.
100 X = PEEK(197) : Y = PEEK(203)
120 IF X = 64 AND Y <> 64 THEN PRINT Y
140 GOTO 100
Here is the table I developed using my real C64C. It is pleasingly alike to the table found on the c64-wiki here.
The table on the wiki indicates that code 63 ($3F) is RUN/STOP but I didn’t include that as the program in its current state can’t test that.
Having acquired the keyboard code for the pressed key, we now need to determine whether or not a SHIFT or CTRL or C= key was simultaneously pressed. To do that we can read memory position 653. It will equal:
1 if SHIFT is pressed
2 if C= is pressed
4 if CTRL is pressed
0 if none of those
So, after reading the matrix and assigning a keyboard code, and determining if a SHIFT or CTRL or C= is simultaneously pressed, the next step is to determine what character should be entered into the keyboard buffer as a result of the key press.
There are four lookup tables:
60289-60353 ($EB81-$EBC1) – for no simultaneous key press
60354-60418 ($EBC2-$EC02) – for SHIFT pressed
60419-60483 ($EC03-$EC43) – for C= pressed
60536-60600 ($EC78-$ECB8) – for CTRL pressed
Let’s look at one or two elements of these lookup tables. I know that if I press A, the keyboard code is 10. PEEK(60289 + 10) gives me 65, which is in fact the PETSCII code for A.
PEEK(60354 + 10) gives me 193, which is the PETSCII code for a playing card spades symbol in a box, which is what I would get on the Commodore if I typed in SHIFT-A.
A statement like IF PEEK(653) = 0 THEN A$ = CHR$(PEEK(60289 + PEEK(197))) shows how the lookup tables work.
Let’s take a look now at the keyboard buffer, which is ten bytes from 631-640 ($0277-$0280) that hold as yet unprocessed key presses. Zero page byte 198 ($C6) holds the number of entries in the buffer – from 0 to 10. The little program below lets you watch the keyboard buffer being filled in, including tracking the number of entries. When an input statement is encountered, the buffer is read in, and the number entries reset to zero. So run the program, and press keys while the loops are running. Be sure that your last key is a RETURN.
100 FOR K = 1 TO 20 105 PRINT CHR$(147) 110 FOR J = 1 TO 5 120 FOR I = 631 TO 640 130 PRINT PEEK(I), 140 NEXT I 150 PRINT PEEK(198) : PRINT
160 NEXT J 170 NEXT K
Here is a kind of fun program that lists itself when run. It puts the characters “L”,”I”,”S”,”T” and RETURN into the buffer, and then the number of entries (5) into 198. When the program is finished, the buffer, including the RETURN, is read and processed by BASIC, and the program lists itself.:
That’s all for now. For a cultural dive into the 8-bit era, I recommend dusting off your copy of Orson Scott Card’s Ender’s Game – it’s a lot of fun.
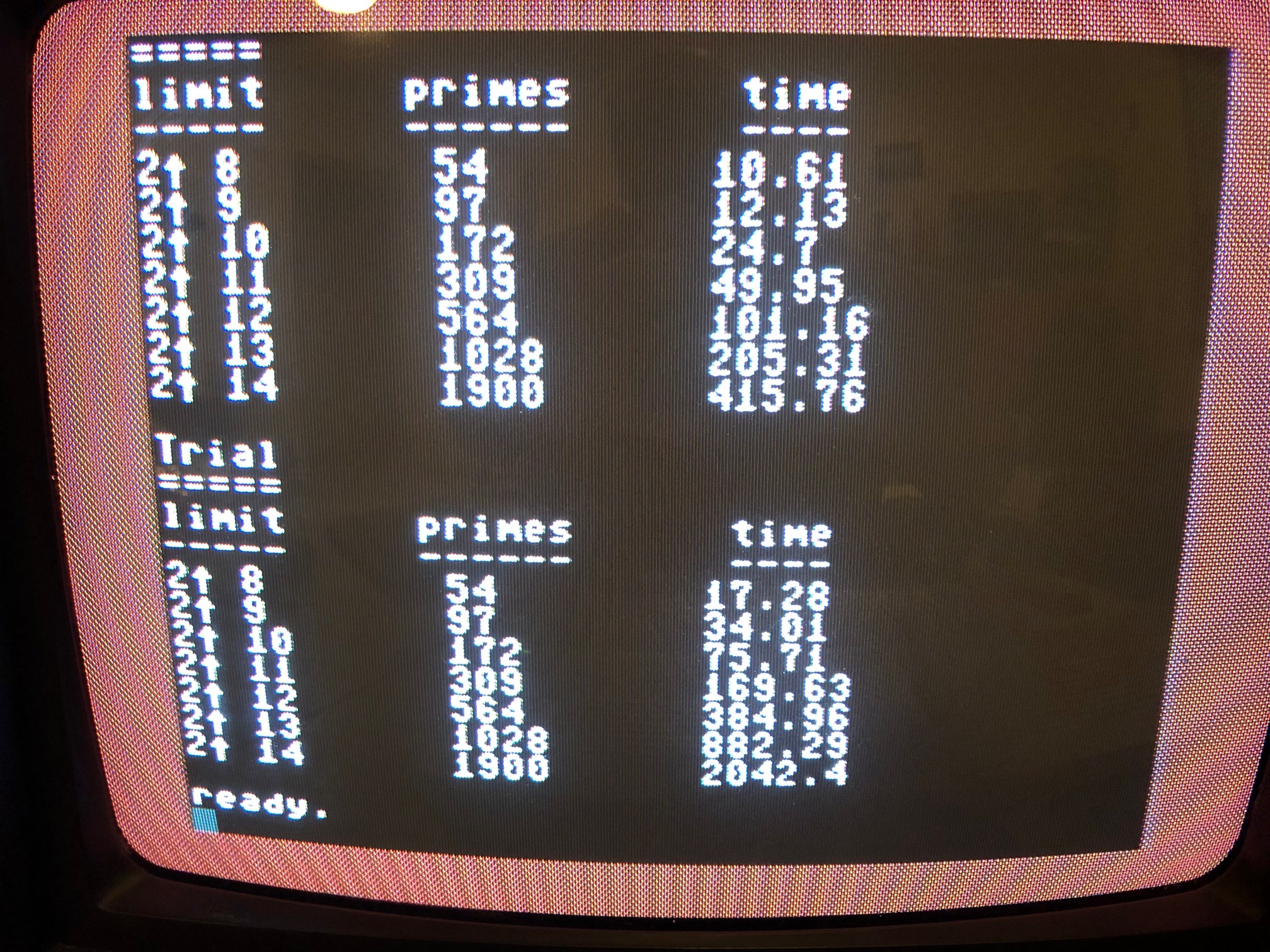
5 print chr$(147)
10 u=10
20 dim a%(2^u + 1)
25 m = int((2^u)/log(2^u))
30 dim b%(int(1.5 * m))
50 print "sieve"
60 print "====="
70 print "limit","primes"," time"
80 print "-----","------"," ----"
100 for n = 8 to u
105 t = time
110 lm = 2^n : sm = int(sqr(lm))
200 for i = 1 to lm : a%(i)=1 : next i
210 a%(1) = 0
500 for p = 2 to sm
520 if a%(p) = 0 then 620
560 for ct = 2*p to lm step p
580 a%(ct) = 0
600 next ct
620 next p
630 pc = 0
640 for i = 1 to lm
660 if a%(i) = 0 then 700
680 pc = pc + 1
700 next i
705 s = (time-t)/60
706 s = int(100*s)/100
500 for p = 2 to sm
520 if a%(p) = 0 then 620
560 for ct = 2*p to lm step p
580 a%(ct) = 0
600 next ct
620 next p
630 pc = 0
640 for i = 1 to lm
660 if a%(i) = 0 then 700
680 pc = pc + 1
700 next i
705 s = (time-t)/60
706 s = int(100*s)/100
710 print "2^";n,pc,s
720 next n
1000 print : print "Trial"
1010 print "====="
1020 print "limit","primes"," time"
1030 print "-----","------"," ----"
1040 for n = 8 to u
1042 lm = 2^n
1045 b%(1) = 2
1050 t = time
1060 pc = 1
1070 for x = 3 to lm
1080 for y = 1 to pc
1090 w = x/b%(y)
1095 if w = int(w) then 1200
1100 if (b%(y)*b%(y)) > x then goto 1120
1110 next y
1120 pc = pc + 1
1130 b%(pc) = x
1200 next x
1270 s = (time-t)/60
1275 s = int(100*s)/100
1300 print "2^";n,pc,s
1400 next n
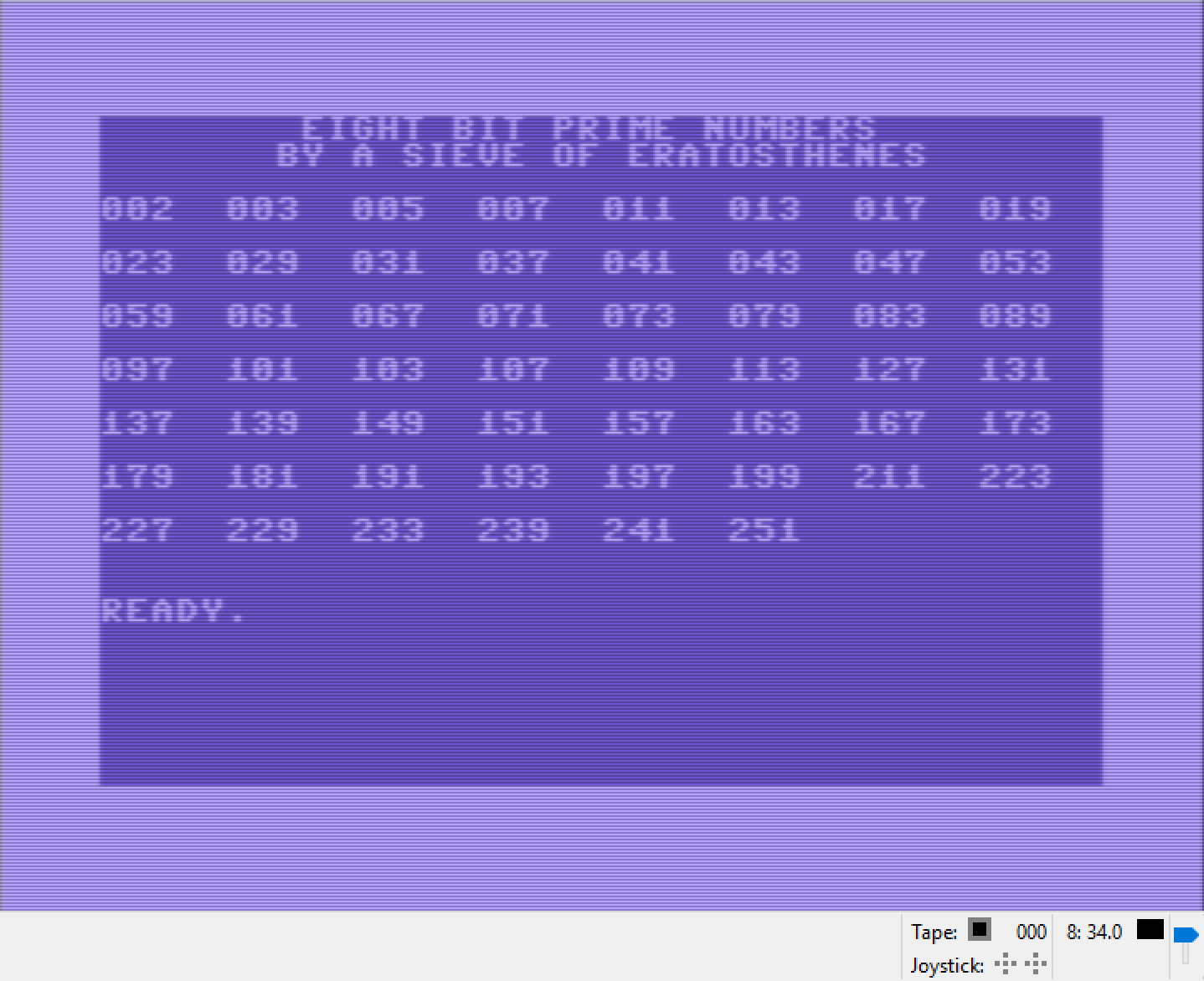
I wrote a short program in assembler, using Turbo Macro Pro, to implement a Sieve of Eratosthenes to find the 8 bit prime numbers.
Right click here to download the disk image: tmpsieve
Here is the screenshot:
The ML program places a basic program in memory that is just:
10 SYS 4096
So, once SIEVE is loaded, (LOAD “SIEVE”,8,1), all one has to do is type RUN to run the sieve.
chrout = $ffd2
sieve = $0900 ; 8 bit sieve
*= $0800
;the 00 byte that starts basic
.byte $00
; pointer to the next basic line
; which is at $080c
.byte $0c,$08
; line 10
.byte $0a,$00
; the basic token for sys
.byte $9e
; a space
.byte $20
; "4096"
.byte $34,$30,$39,$36
; 00 for the end of the basic line
.byte $00
; 00 00 for the end of the basic
; program
.byte $00,$00
w1 = $0880; working variable
w2 = $0881; working variable
w3 = $0882; working variable
w4 = $0883; working variable
w5 = $0884; working variable
hx = $0885; holder for x
hy = $0886; holder for y
hdig = $0887; hundreds digit
tdig = $0888; tens digit
odig = $0889; ones digit
head = $0890 ; header
; this is the header
; it is 68 bytes
*= $0890
;[clr][sp][sp][sp]
.byte $93,$20,$20,$20
;[sp][sp][sp][sp]
.byte $20,$20,$20,$20
;[sp]eig
.byte $20,$45,$49,$47
;ht[sp]b
.byte $48,$54,$20,$42
;it[sp]p
.byte $49,$54,$20,$50
;rime
.byte $52,$49,$4d,$45
;[sp]num
.byte $20,$4e,$55,$4d
;bers
.byte $42,$45,$52,$53
;[cr][sp][sp][sp]
.byte $0d,$20,$20,$20
;[sp][sp][sp][sp]
.byte $20,$20,$20,$20
;by[sp]a
.byte $42,$59,$20,$41
;[sp]sie
.byte $20,$53,$49,$45
;ve[sp]o
.byte $56,$45,$20,$4f
;f[sp]er
.byte $46,$20,$45,$52
;atos
.byte $41,$54,$4f,$53
;then
.byte $54,$48,$45,$4e
;es[cr][cr]
.byte $45,$53,$0d,$0d
*= $1000
jmp main
mult10 ; multiply by 10 subroutine
asl a
sta w1
asl a
asl a
adc w1
rts
; now, in order to output base-10
; values to the screen we need
; to get a char which represents
; each digit in the base-10
; representation of the 8-bit
; number to be output
; we will store the hundreds place
; digit in hdig, the tens plae
; digit in tdig, and the ones
; place digit in odig
; get hundreds digit subroutine
gethundig
cmp #$c8 ; is a gt 200?
bcc hless200
ldx #$02 ; if here, hdig is
stx hdig ; 2 so store it
sec
sbc #$c8 ; subtract 200 from
rts ; a and return
hless200
cmp #$64 ; is a gt 100?
bcc hless100
ldx #$01 ; if here, hdig is
stx hdig ; 1 so store it
sec
sbc #$64 ; subtract 100 from
rts ; a and return
hless100
ldx #$00 ; if here, hdig is
stx hdig ; 0 so store it
rts
gettendig
; when this sub is run, a is 0-99
; start by putting a 9 in x,
; multiplying that by 10, then
; seeing if 90 is higher than the
; test number - if not, tdig is 9,
; and so on
sta w2; preserve a
ldx #$09
tryaten
txa
jsr mult10
sta w3; w3 = 90,80,70,etc
lda w2
cmp w3
bcc tennotfound
txa ; we hav found our ten
sta tdig
lda w2
sec
sbc w3
rts ; we've found the digit,
; and left the ones place
; in a - so return
tennotfound
dex ; try the next lower
bne tryaten
ldy #$00; if here, tdig=0
sty tdig
lda w2
rts
getonedig
sta odig; by this time, the
; ones digit is all that
; is left in a
rts
getdigs
jsr gethundig
jsr gettendig
jsr getonedig
rts
printdigs
jsr getdigs
lda hdig
ora #$30; convert to ascii
jsr chrout
lda tdig
ora #$30
jsr chrout
lda odig
ora #$30
jsr chrout
lda #$20; two spaces
jsr chrout
jsr chrout
rts
dosieve
ldx #$00; use x to index loop1
lda #$01
loop1
sta sieve,x; fill the sieve wit
inx
bne loop1
lda #$00
ldx #$00
sta sieve,x; 0 is not prime
inx
sta sieve,x; 1 is not prime
; w1 is counter as we step
; w2 is step size
lda #$01
sta w1
sta w2
nextpass
inc w2; if we are on first pass
; through sieve, we just
; increased step from 1 to 2
; which is what we want
lda w2; the step size is also
; the first element in
; any pass
sta w1
cmp #$10; have we reached 16?
; if so, we ar done
bne not16
rts
not16
ldx w2
lda sieve,x; does x point to a
; zero in the sieve?
beq nextpass ; ifso x composite
; so move on
nextstep
lda w1
txa
beq nextpass; we've stepped all
; the way through
; sieve so increase
; step
lda w1
adc w2 ; add the step
bcs nextpass; if the carry flag
; is set we're past
; the end of the
; sieve so nextpass
sta w1
tax ; update x pointer
lda #$00
sta sieve,x; x not prime so
; mark with a zero
jmp nextstep
printheader
ldx #$00
phloop
lda head,x
jsr chrout
inx
cpx #$44
bne phloop
rts
main
jsr dosieve
jsr printheader
;sieve now marks primes
;with a 1 - step and
;print primes
ldy #$00
sty w5; w5 is primes on
; this current line
probesieve
lda sieve,y
beq movetonext
tya
stx hx
sty hy
jsr printdigs
ldy hy
ldx hx
inc w5
lda w5
cmp #$08; end of line?
bne movetonext
lda #$0d
jsr chrout
lda #$00
sta w5; reset line index
movetonext
iny
bne probesieve
lda #$0d
jsr chrout
jsr chrout
rts